目次
- Dockerとは
- Dockerの特徴
- Dockerのインストール
- InfluxDBとは
- InfluxDBのインストール
- InfluxDBのセットアップ
- バケットの確認・作成
- Line Protcolを使ってバケットにデータを挿入
- Data Explorerでデータの確認
Dockerとは
Dockerは、ソフトウェアを「コンテナ」という軽量で独立した環境にパッケージ化して実行・管理できる仮想化技術である。このコンテナは、必要なすべての要素(コード、ライブラリ、設定ファイルなど)を1つにまとめることができる。このようなパッケージは「イメージ」と呼ばれ、このイメージを用いてコンテナを作成・実行する。
Dockerの特徴
軽量で高速
- Dockerはコンテナ技術を使用しており、仮想マシン(VM)と比較して軽量で高速に動作する。コンテナはホストOSのカーネルを共有するため、オーバーヘッドが少なく、起動が非常に速い。
効率的なリソース利用
- DockerコンテナはホストOSのカーネルを共有するため、仮想マシンのように各コンテナごとにフルOSを起動する必要がない。これにより、ディスクスペースの使用量が少なく、メモリやCPUなどのリソースを効率的に利用できる。
チームでのコンテナ管理に向いている
- Dockerはコンテナをコードとして管理できるため、複数の開発者や運用担当者が同じ設定や環境を共有できる。これにより、チーム全体で一貫した環境を維持しやすくなる。
どこでも動作する
- Dockerイメージは、作成された環境(ローカルマシンなど)と同じように、他のどのマシンでも(そのマシンがDockerを実行していれば)動作する。これにより、「私のマシンでは動作するのに、本番環境では動作しない」という問題を解消できる。
Dockerのインストール
・Docker 公式サイト からインストール
参照:https://www.docker.com/
InfluxDBとは

引用元:https://www.niagaramarketplace.com/influxdb.html
InfluxDBは、時系列データを効率的に保存・管理・分析するためのデータベースである。時系列データとは、時間の経過とともに変化するデータのことで、センサーの読み取り値、CPU使用率、株価の変動などが例として挙げられる。
InfluxDBのインストール
① Dockerを使用したインストール
1.「Docker」イメージを取得:
docker pull influxdb2. 「influxDBコンテナ」を起動:
docker run --rm --name influxdb -p 8086:8086 -v PWD:/var/lib/influxdb influxdb
➁ Arch Linuxでのインストール
1. 「Arch Linux」 へのインストール:
sudo pacman -S influxdb
2. 「influxDBコンテナ」を起動:
sudo systemctl start influxdb
➂ Ubuntuでのインストール
1. 「Ubuntu」 へのインストール:
wget https://dl.influxdata.com/influxdb/releases/influxdb2-2.6.1-amd64.deb
sudo dpkg -i influxdb2-2.6.1-amd64.deb
wget https://dl.influxdata.com/influxdb/releases/influxdb2-client-2.6.1-amd64.deb
sudo dpkg -i influxdb2-client-2.6.1-amd64.deb
2. 「influxDBコンテナ」を起動:
sudo systemctl start influxdbInfluxDBのセットアップ
① 下記のコマンドでinfluxDBの「Container ID」を確認
docker ps
➁ 下記のコマンドで「Container ID」を指定しコンテナの中に入る
※「your container id」は自身のIDを入れる
docker exec -it your container id sh
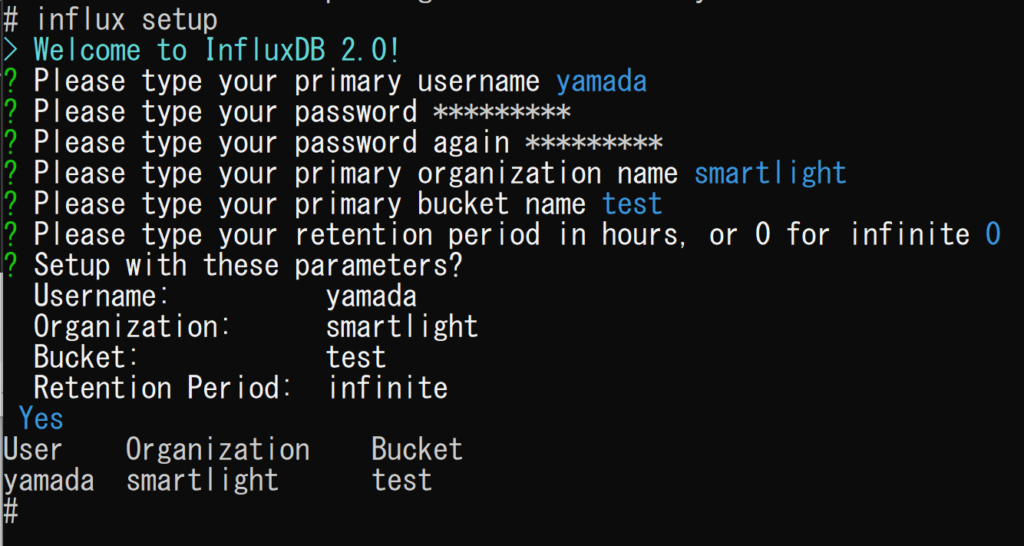
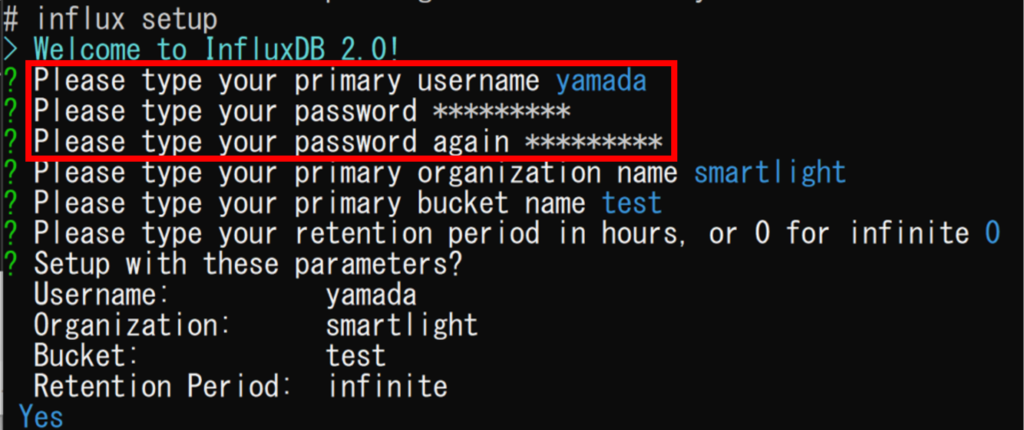
➂ 下記のコマンドで「ユーザーのセットアップ」を行う
セットアップに必要な情報を求められるので以下のように入力する
influx setup1. 「Please type ~ username」… 自身の名前
2. 「Please type ~ password」… 自身のパスワードを設定
3. 「Please type ~ password again」… パスワードの確認
4. 「Please type ~ organization name」… 自身の組織名
5. 「Please type ~ bucket name」… バケットの名前
6. 「Please type ~ infinite 0」… DBへの保持期間の指定(0と入力すると無期限)
7. 「Confirm (Y/n):」… セットアップの確認(yと入力し、セットアップ完了)
➃ 下記のコマンドで「ユーザーの確認」が可能
influx auth list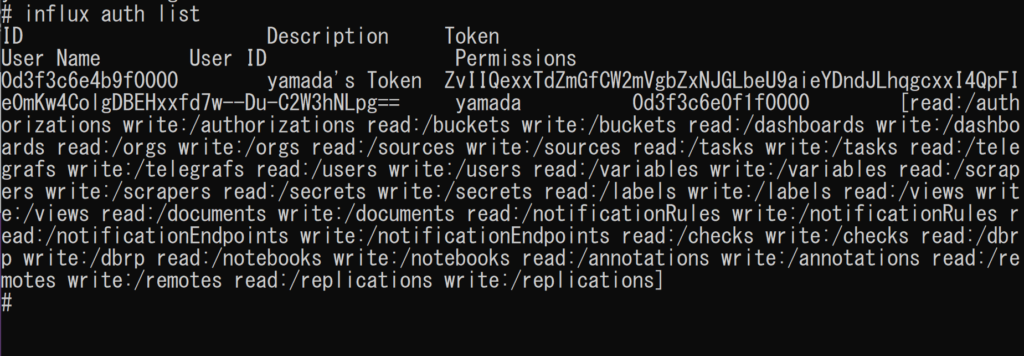
バケットの確認・作成
① ブラウザから「InfluxDB」にアクセス
・ユーザーのセットアップで決めたユーザー名とパスワードでサインインする(下の赤枠)
➁ バケットの確認と作成
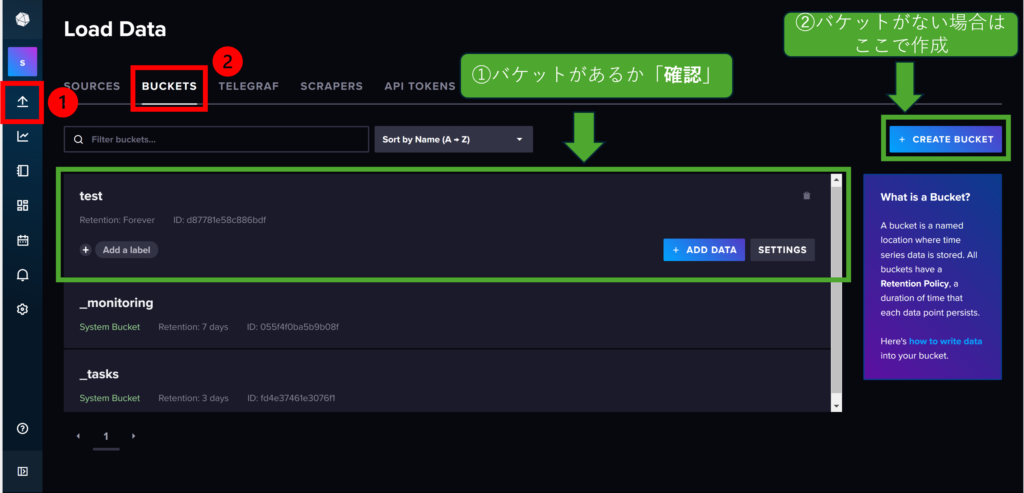
・「↑マーク」を押し、「BUCKETS」を選択する
・ 下の欄に先程作成したバケットがあるか確認する
・ バケットがない場合は、「+ CREATE BUCKET」でバケットを作成する
Line Protocolを使ってバケットにデータを挿入
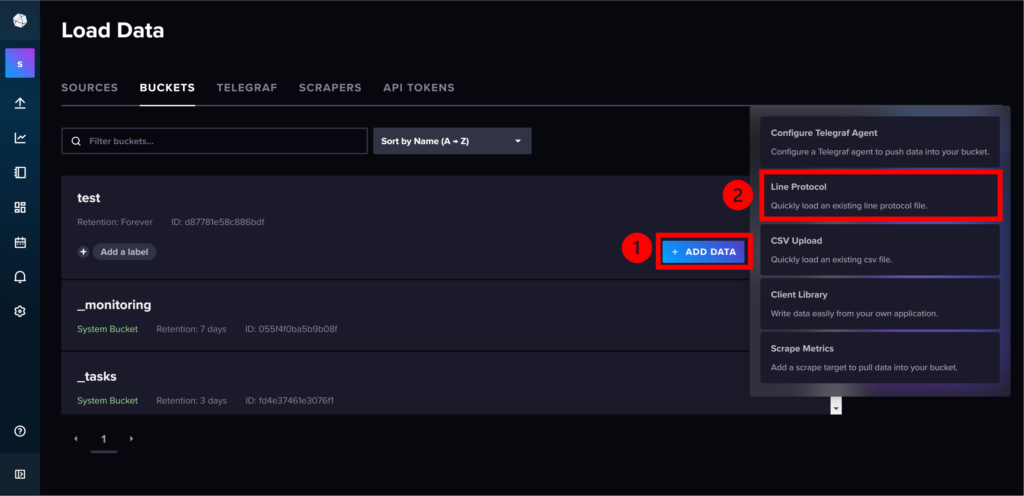
・「ADD DATA」を押して「LineProtocol」を選択する
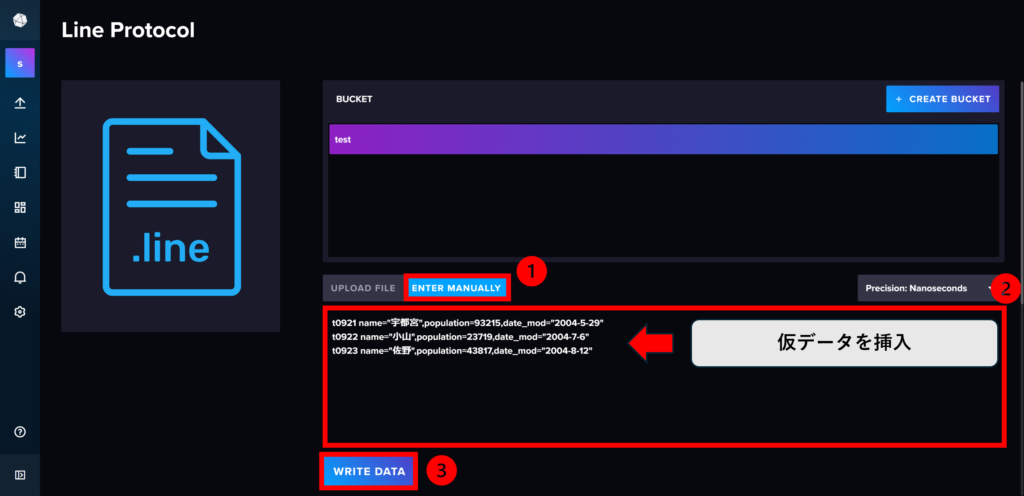
① 「ENTER MANUALLY」を選択
➁ 下記に提示している仮データを挿入
➂ 「WRITE DATA」を押してデータを書き込む
t0921 name="宇都宮",population=93215,date_mod="2004-5-29"
t0922 name="小山",population=23719,date_mod="2004-7-6"
t0923 name="佐野",population=43817,date_mod="2004-8-12"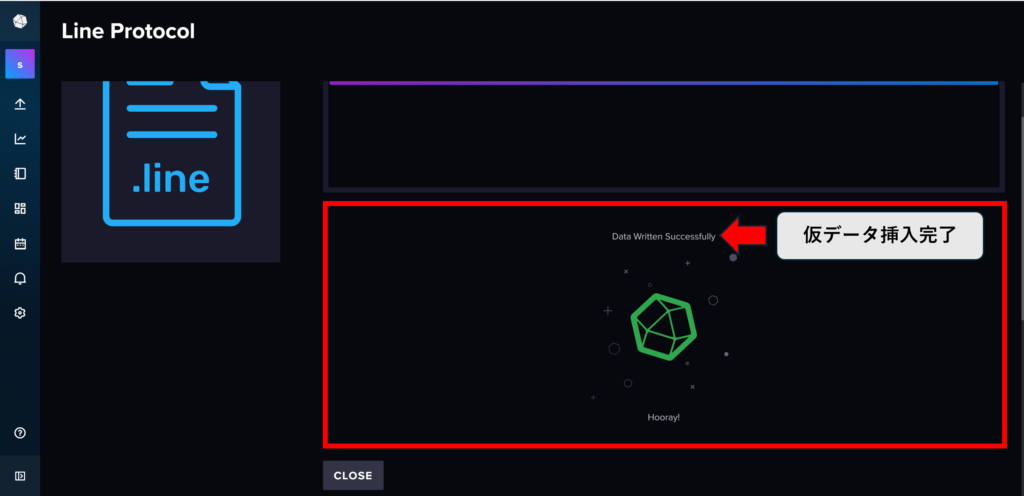
・上の画像の通りになっていれば仮データ挿入に関しては完了
Data Explorerでデータの確認
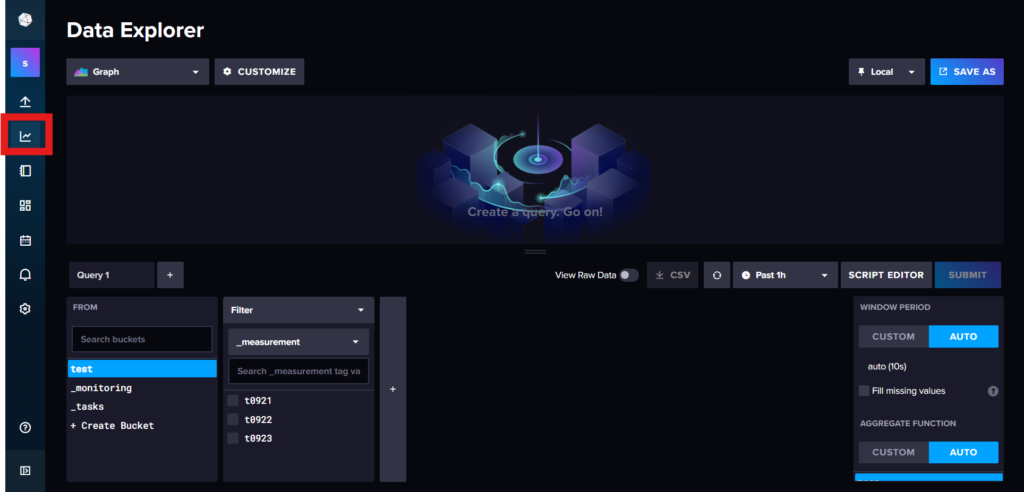
・ 左の欄にある「グラフマーク」を押し、「Data Explorer」を開く
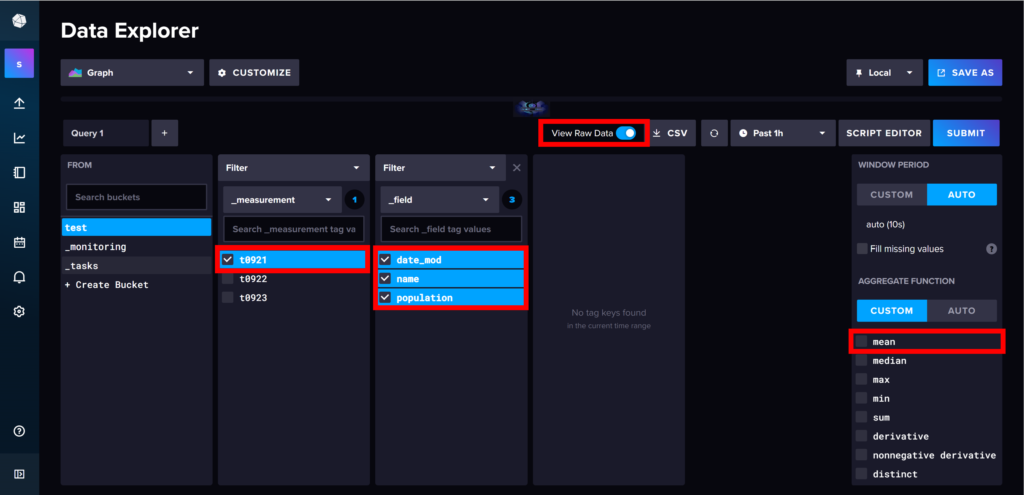
① 「Measurement Tag」を選択
(メジャーメントタグ … データを識別するための情報・値)
➁ 「field」で3つの要素にチェックを入れる(日付・名前・人口)
➂ 右の欄にある「AGGREGATE FUNCTION」を「CUSTOM」に変更し、
「mean」を削除
➃ 画面の上部にある「View Raw Data」をオンにする
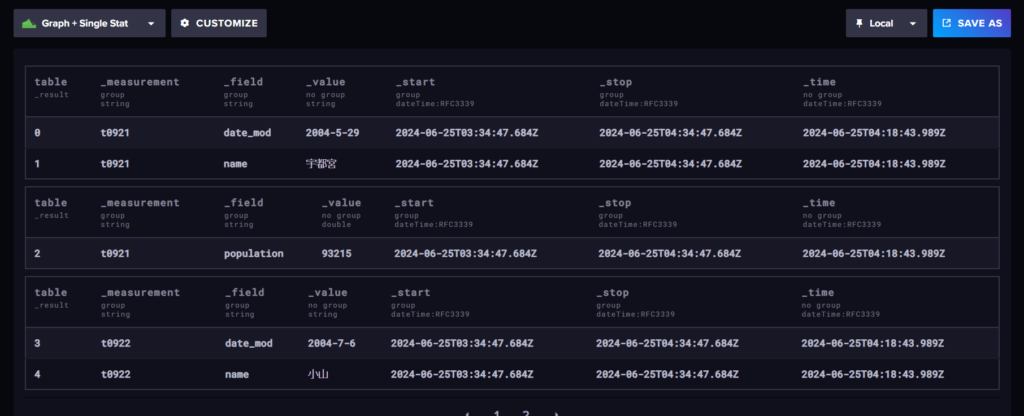
・最後に「SUBMIT」を押し、上の画像のようにデータが正しく表示されれば完了